With disruption in both demand and supply chains now a constant feature in so many sectors, many companies have accelerated the implementation of new technologies and new ways of working as they chase better resilience, agility and control in their operations. Those initiatives typically involve digital transformation, with the hope that better visibility and analytics of the data sets that today permeate businesses will achieve those goals. All too often, though, those change initiatives fail to deliver on the expected returns, stumbling at the outset when the quality of the business’s data is found to be wanting. This is typical when it comes to materials master data, i.e. the data on inventory, whether raw materials, WIP, finished products or MRO (maintenance, repair and operations) spare parts.
This messy situation is a common problem and results in inefficiency, confusion and waste; those translate into higher costs. For instance, inventory levels become fatter than required, procurement becomes excessive and materials costs rise. In the current environment, when cost control is so essential to business continuity, this shouldn’t be tolerated.
“Change initiatives fail to deliver when the quality of the business’s data is found to be wanting”
The answer is to clean the master data, removing errors and duplication, adding missing data, ensuring that data is current and that it is well-structured. Synopps, our business partner, offers a wide range of services in MDM.
The Importance of clean master data
At its heart, corporate master data is the structured dataset of materials, goods, works and services of a company. For materials master data, this is the reference dataset that is necessary to ensure order and effectiveness in materials management, from procurement, through to production warehouse management and movements. Normally, it will contain the serial number, name, description and characteristics of each stock keeping unit (SKU) – each item – that a company works with. It may also include the details of the supplier, the supplier’s part number and other procurement-related data.
Despite its importance, materials master data commonly suffers from a lack of due diligence, with errors creeping in cumulatively from bad data migration and database management, poor data generation processes and immature data governance. The results of this situation include:
- Lower service levels
- Increased working capital requirements
- Excessive purchasing
- Higher levels of obsolescent and obsolete stock
- Lack of critical stock
- More frequent operations stoppages
- Wasted effort in inventory accounting and reporting processes
The net effect of these is that operations are more costly and less efficient to run.
By resolving those issues and reducing costs, a clean master data set and mature data processes – including procurement, inventory and financial management processes that affect that data – brings benefits in business process transparency, reducing material waste and increasing profitability.
Cleaning master data
The overall goal of cleansing master data is to have a single, consistent and complete dataset to use in the business. This goal is achieved by:
- Setting data according to a standard format
- Ensuring the data is accurate and up-to-date
- Removing redundancy such as duplicate line items
- As far as is practicable, completing empty fields with missing data
Traditionally, these tasks are extremely onerous, requiring dedicated time and significant effort over a long time to gather and assess the dataset, then go through each item and complete those cleansing activities. In most cases, the task is never-ending as “bad” data is continually added; ultimately, the job is set aside and never completed. However, improved analytical tools and adopting a systems approach mean that that no longer has to be the case. By involving the right people, implementing the right processes and supporting those with the right tools, cleaning master data can be done quickly, accurately and consistently.
A Modern Approach
The use of modern analytical tools in business operations is not new. For a long time, they have been used to improve demand forecasting, to set minimum and maximum inventory levels, and to identify bottlenecks in operations. More recent advances now bring together two powerful abilities: advanced modelling and automation. Those significantly reduce the manual effort required to render a good dataset. By using them, the process to cleanse master data involves four steps:

Step 1: Master Data Audit
First, the data is collated and assessed automatically to check for errors, evaluate its completeness and identify duplication. The assessment categorizes the data according to what faults it has.
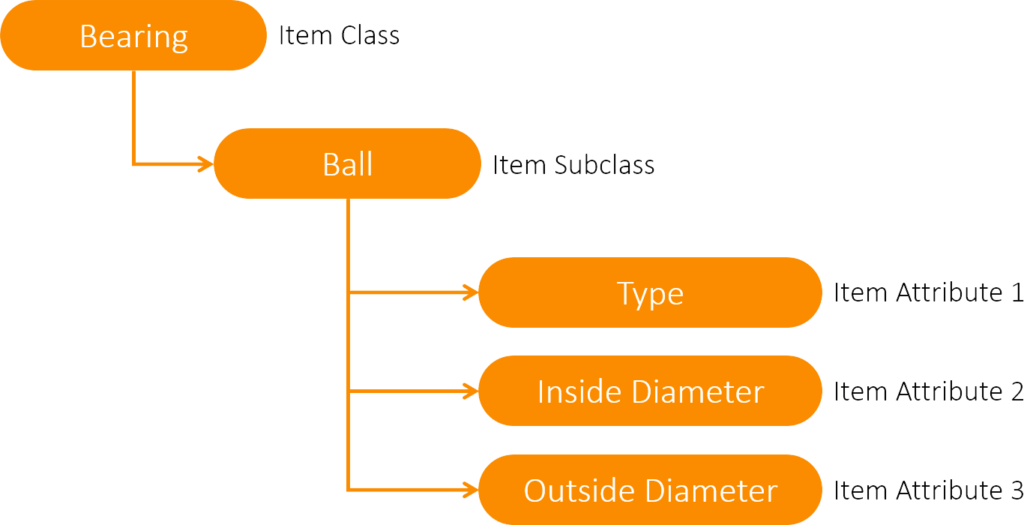
Step 2: Templates DevelopmentTemplates should be used to ensure that master data is structured correctly and consistently, defining what fields are required and how they should be populated. Those templates may adhere to industry or sector standards, such as ISO 8000:115 (“Data quality — Part 115: Master data: Exchange of quality identifiers: Syntactic, semantic and resolution requirements”). Alternatively, they may be set by a company according to its own specific needs. While not every characteristic may need to be included in it, the template should prescribe the minimum needed to describe and uniquely identify an item. That includes defining the standards for describing an item’s class (and any subclasses), as well as characteristics such as physical dimensions and what it is made of. For instance, a ball bearing may be described thus:
The template should prescribe, for instance, how each field is expressed, such as the length of the field (i.e. the number of characters permissible) and the syntax that the field is to be expressed in (e.g. text, number).
Using the advanced capabilities of solutions such as SynOpps, the issues previously identified are addressed automatically via those tools, as far as is practicable. The first part of this is to ensure that the individual characters used in the data are correct. This means for example:
- Replacing untypable characters
(e.g. BOLT STAINLESS STEEL ½ NC 1-1/2 becomes BOLT STAINLESS STEEL 1/2 NC 1-1/2) - Removing redundant characters
(e.g. RADIATOR—-HOSE ZMZ 409 becomes RADIATOR-HOSE ZMZ 409) - Correcting syntax and spelling errors
(e.g. FLTER 1R-0042 becomes FILTER 1R-0042) - Replacing letters when they are incorrectly used as numbers
(e.g. BOLT CATERPILLAR 1O – 3444 becomes BOLT CATERPILLAR 10 – 3444)
Next, the data blocks (essential parts of descriptions, i.e. class, subclass, part numbers, characteristics, etc.) are automatically recognized and set out according to the requisite templates. More specifically, this means:
- Identifying class and subclass of the record
(i.e. “oil seal”, where “oil” is the subclass and “seal” is the class) - Identifying characteristics and their values
(i.e. 10 x 20MM, 0.5 kg etc) - Identifying codes and their variations
(i.e. ISO 8752-79) - Confirming and validating data blocks, such that once data blocks are extracted, they are validated to eliminate any errors
- Redistributing the order of blocks according to the template, and typical templates can consist of: class + subclass + manufacturer + part number + characteristics
- Formatting blocks according to the template
(for instance, use of upper or lower case) - Enriching records with data
(e.g. adding missing data to the block in the description)
The final activity in this step is carrying out another check for duplicate items, which can arise once the data is cleaned and set out with the right structure. A more contextual analysis is also required to deal with synonyms, for instance, and a good approach that maximizes accuracy is to compare several aspects of item data, such as:
- Comparing item classes and considering synonyms
- Comparing codes and their variations, without considering formatting
(e.g. capital or lower case) - Comparing values of characteristics rather than their textual representation
(e.g part numbers are recognized regardless of the way that they are spelt, i.e 1R0042, 1R-0042 or 1r 00 42)
It is worth adding that, despite the best efforts, it may not always be possible to have complete data. Items may be sitting in inventory for many years and their suppliers may go out of business, losing information as they do. Even if those firms are still a going concern, published data, such as part numbers or physical characteristics, may be missing. In those cases, alternative approaches are needed including physically examining and measuring items.
Step 4: Master Data Management
Cleaning master data is not something that can be done once and forgotten about. Without the right processes and governance in place, the quality of the data will quickly erode resulting in the same consequences as before. To avoid this, effective data management should be an active part of operations, articulated and realized through good processes, governance and – above all – training. This begins with a clear definition of the processes that create and modify master data, and the roles and responsibilities of those who carry out those processes. Those processes must also include the steps and tools that check data quality continuously. For instance, before new items’ data being added to the master database, its format must be confirmed to be correct and intelligent agents can check that the item to be added isn’t a duplicate of an existing one.
The Size of the Prize
Having conducted several data cleansing efforts, we have found that implementing master data cleansing typically delivers:
1. Lower excess inventory; removing duplicate items reduces MRO items stock by 2-10% and turnover is increased, while working capital is released and related excess costs are reduced, all contributing to a better margin
2. Minimized false stockouts; when data is consistent and clean, service levels are increased by 5-10%, while the probability of false stockouts is reduced, with every stock unit visible and available to operations
3. Reduced direct purchases; when duplicate invisible stock is identified, immediate cash savings of 1-5% of annual procurement can be achieved since extraneous purchase is avoided
Benefits of Clean Master Data:
> Lower inventory levels with no loss of service levels
> Minimal false stockouts
> Reduced procurement spend
Master data cleansing seems obvious and a quick-win. However, it is many often underestimated what is needed, either only deploying very basic tools, such as Excel spreadsheets, or purchasing the tool and ignoring the wider change management that is needed. The advent of international standards, such as ISO 8000:115, are expected to improve the quality of master data. The reality is that until those standards are globally adopted, there will be a need for proactively cleaning materials master data. At the very least, the data will need to be structured according to the templates those standards call for, and that task is one that automated tools are far more efficient and less expensive at doing.

